
Two weeks into the course “Data Science” at Harvard, here are some reflections and a doodle that I made during the course.
📈 Serious data science that leads to data-based decision making follows a five step model (my simplified modification from Harvard’s original model):
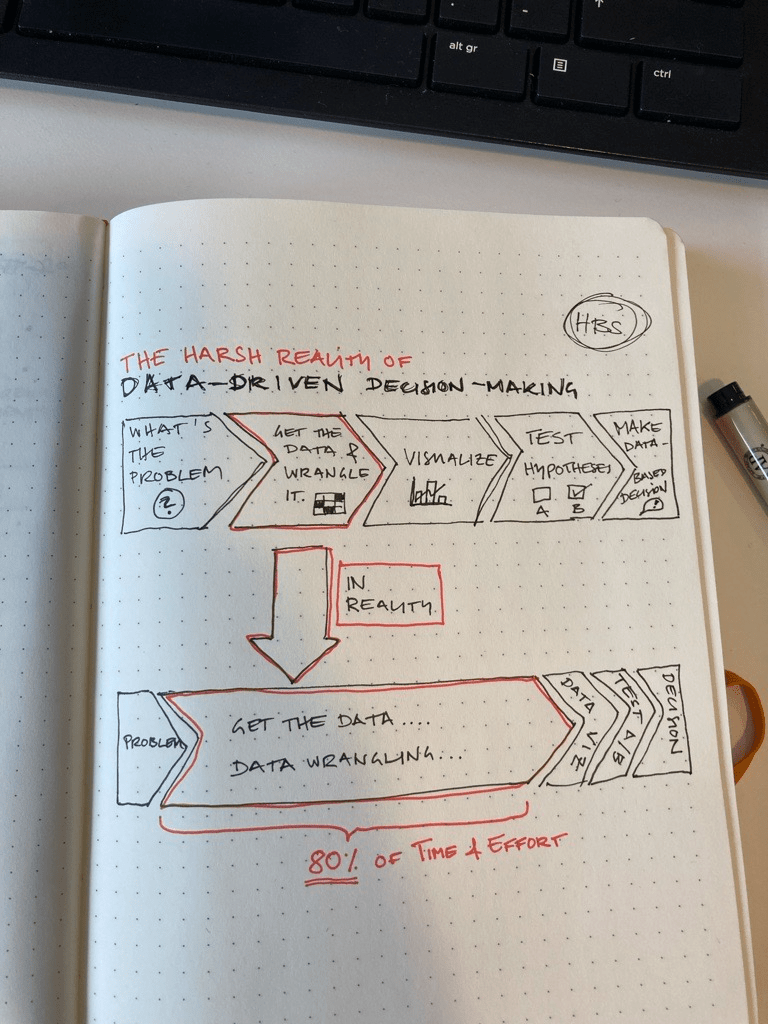
1. What’s the problem?
Make a specific, measurable definition of what the problem is. My experience: Often people pass over this stage too quickly, just to discover that they do not really know what problem they want to solve. Make it specific, make it measurable.
2. Get the data & wrangle it
Data wrangling is a data sciency work for the process of getting the data table in shape for further analysis. And here is the deal: Data aquisition and preparation means blood, sweat and tears and takes usually up 80% of time and effort. It’s not glamorous, but it’s a dirty job that someone’s gotta do. Here is where you can end up collecting garbage (and as everybody knows “Garbage in, garbage out.”) or gold nuggets. Especially in my sector, mental healthcare, it can be difficult to get hold of good quality data. However, if you want to be able to trust your data, allocate time and resources to get this step right.
3. Visualize
Look at the data visually early on. Make a graph. Make many different graphs. And then some more. This helps you to get to know your data and develop hypotheses about how you could solve your problem.
4. Test your hypothesis from step 3
Is it A or B? Use statistical modelling to test if the data supports either one.
5. Based on 4., make your decision
Important: It’s not the data or the statistical test or the AI that makes the decision, it’s humans with experience and competence. Some of the best decisions may be the ones that go against the data, for good, human reasons. Also: Follow up with further data collection if your decision was the right one or not.
💡 i hope this was helpful. Let me know your experiences with data-driven decision processes!
